Apache Lucene Core Terminology
Updated
•7 min readLucene
Lucene can efficiently index the data that needs to be searched. This is being used in Elastic Search, Solr, etc.
Terminology:
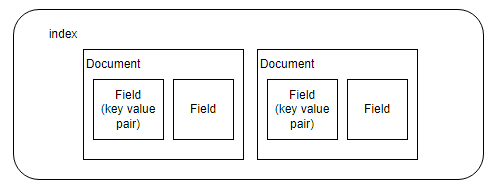
Index:
- A collection of documents, typically with the same schema ("not a table")
- This is similar to a table in relational database.
- With comparision to the tables in RDBMS, index doesn't require any schema.
- In a index we can add or insert and retrive a document but cannot be modified it directly.
Document:
- A record; the unit of search; the thing returned as search results ("not a row").
- This is similar to a row in RDBMS.
- There can be one or more documents in an index.
- Each document written to the index is assigned a sequence id called DocId.
Field:
- A typed slot in a document for storing and indexing values ("not a column")
- A document can contain one or more fields.
- Lucene provides different type of fields - StringField, TextField and NumericDocValuesField.
Term:
- Value extracted from source document, used for building the inverted index.
- The smallest unit of index and search in Lucene.
- A field consists of one or more terms. A term is produced when a field is passed through Analyzer (typically Tokenizer)
Term dictionaryis used for performing conditional search on term.- A dictionary containing all of the terms used in all of the indexed fields of all of the document.
FieldType:
- This is class contains different attributes which decides how the field to be indexed.
| Attributes | Description |
| stored | indicates whether to save the field |
| tokenized | Only TextField's can be tokenized, this represents whether or not to tokenize |
| omitNorms | Lucene enables every field in each document to have normalization factor. Normalization is a coefficient related to the scoring during searches. |
| indexOptions | Optional parameters for inverted index. NONE, DOCS, DOCS_AND_FREQS, DOCS_AND_FREQS_AND_POSITIONS, DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSET |
Segment:
- An Index is composed of one or more sub-indexes called segments.
Lucene internal:
- When Lucene writes data to an in-memory buffer.
- When memory buffer reaches a threshold (certain amount), it will be flushed to become a Segment.
- Every segment has its own independent index and are independently searchable.
- Data in segment cannot be modified, this prevents random writes. But this can be deleted
- Data is written as Batch or as an Append to achieve high throughput.
- The deletion method does not change the file in its original, internal location, but the DocId of the document to be deleted is saved by another file to ensure that the data file cannot be modified.
- Index queries will query multiple Segments and merge the results, as well as handling deleted documents.
- In order to optimize queries, Lucene has a policy to merge multiple segments. (Refer LSM's merge process)
- Before segments are flushed or committed, data is stored in memory and is unsearchable. This is another reason why Lucene is said to provide near-real time and not real-time queries.
Sequence Number:
- Sequence Number (called DocId) is like a primary key in RDBMS to identify a row. Lucene Index identifies a Doc by DocId.
- DocId are unique within a Segment.
- DocId's are not continuous, when Documents are deleted there will be gap.
- DocId's corresponding to a document can change, usually when Segments are merged.
- DocId is basically an int32 value starting from 0
About LSM:
- LSM tree (log-structured merge-tree) is a data structure typically used when dealing with write-heavy workloads. The write path is optimized by only performing sequential writes.
- LSM trees are persisted to disk using a Sorted Strings Table (SSTable) format. As indicated by the name, SSTables are a format for storing key-value pairs in which the keys are in sorted order.
- SSTable consist of multiple sorted files called segments. These segments are immutable once they are written to disk.
- LSM is code datastructure behind many database like Cassandra, BigTable
What is Inverted index?
- Internal data structure that maps terms to documents by ID.
Say we have documents, containg below fields
doc1 = {"title":"big data in action"}
doc2 = {"title":"big table in action"}
doc3 = {"title":"sql table in action"}
- The above can be stored in inverted index:
big = [doc1,doc2] data= [doc1] in= [doc1,doc2,doc3] action= [doc1,doc2,doc3] - So if we search for data we get doc1
Code Focus:
- How to add an document to an Index?
using
IndexWriter - How to serach or retrieve documents from an index?
using
IndexSeracher
Creating Index and adding documents, fields
StandardAnalyzer analyzer = new StandardAnalyzer();// defining a standard analyzer
Directory index = new RAMDirectory(); // We are using in memory indexer
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(index, config);
Document doc = new Document(); // create document object
// Add fields to the document
// TextField with content that needs to be tokenized
doc.add(new TextField("username", "tom", Field.Store.YES));
// StringField where we content we DON'T want to be tokenized
doc.add(new StringField("phone", "02123345, Field.Store.YES));
doc.add(new TextField("username", "Barry", Field.Store.YES));
doc.add(new StringField("phone", "02123347,
Field.Store.YES));
//Add the document to index
writer.addDocument(doc);
Querying the index
serachString = "tom"
Query query = new QueryParser("username", analyzer).parse(searchString);
int perPageHit = 10;
IndexReader reader = DirectoryReader.open(index); // RamDirectory
IndexSearcher searcher = new IndexSearcher(reader);
TopDocs docs = searcher.search(query, perPageHit);
ScoreDoc[] hits = docs.scoreDocs;
//Iterate the matched document
System.out.println(hits.length + " hits.");
for(int i=0;i<hits.length;++i) {
int docId = hits[i].doc;
Document d = searcher.doc(docId);
System.out.println(d.get("username") + " - " + d.get("phone"));
}
reader.close();
- There are multiple options to query the index, refer the documents for FuzzyQuery, wildcart, etc.
Additional info about the index
- Each segment index maintains below :
| Element | Description |
Field names. | This contains the set of field names used in the index. |
Stored Field values. | For each document, this contains a list of attribute-value pairs, where the attributes are field names. These are used to store auxiliary information about the document, such as its title, url, or an identifier to access a database. The set of stored fields are what is returned for each hit when searching. This is keyed by document number. |
Term dictionary. | A dictionary containing all of the terms used in all of the indexed fields of all of the documents. The dictionary also contains the number of documents which contain the term, and pointers to the term's frequency and proximity data. |
Term Frequency data. | For each term in the dictionary, the numbers of all the documents that contain that term, and the frequency of the term in that document if omitTf is false. |
Term Proximity data. | For each term in the dictionary, the positions that the term occurs in each document. Note that this will not exist if all fields in all documents set omitTf to true. |
Normalization factors. | For each field in each document, a value is stored that is multiplied into the score for hits on that field. |
Term Vectors. | For each field in each document, the term vector (sometimes called document vector) may be stored. A term vector consists of term text and term frequency. To add Term Vectors to your index see the Field constructors |
Deleted documents. | An optional file indicating which documents are deleted. |
- Below details the extension of Lucene files
| Name | Extension | Brief Description |
| Segments File | segments.gen, segments_N | Stores information about segments |
| Lock File | write.lock | The Write lock prevents multiple IndexWriters from writing to the same file. |
| Compound File | .cfs | An optional "virtual" file consisting of all the other index files for systems that frequently run out of file handles. |
| Fields | .fnm | Stores information about the fields |
| Field Index | .fdx | Contains pointers to field data |
| Field Data | .fdt | The stored fields for documents |
| Term Infos | .tis | Part of the term dictionary, stores term info |
| Term Info Index | .tii | The index into the Term Infos file |
| Frequencies | .frq | Contains the list of docs which contain each term along with frequency |
| Positions | .prx | Stores position information about where a term occurs in the index |
| Norms | .nrm | Encodes length and boost factors for docs and fields |
| Term Vector Index | .tvx | Stores offset into the document data file |
| Term Vector Documents | .tvd | Contains information about each document that has term vectors |
| Term Vector Fields | .tvf | The field level info about term vectors |
| Deleted Documents | .del | Info about what files are deleted |
References:
150 views